Disney movies haven't been the same for a few years, and I've been missing the magic. Just me? Disagree? The data is all there, let's web scrape and find out.
The Downfall of Disney? Once upon a Web Scraper
Okay, downfall may be a little dramatic, but if Disney continues at the rate it's going, I may not be far off. I used to be obsessed with the MCU. I loved watching all the theory videos on YouTube and was so excited every time a new movie was announced, but when, epic though it was, Endgame managed to kill off or fatally change many of my favorite characters, I knew the MCU, and Disney as a whole, would never be the same.
Around the same time in 2019 and 2020 Disney’s live-action remakes churned out some interesting choices with a not-at-all-live-action “live action” Lion King including “Can You Feel the Love Tonight” sung in the middle of the day and the titular character of Mulan’s fighting spirit being replaced with magical chi superpowers, in other words completely missing the points of some of the old stories. The animations are still beautiful and the stories are still enjoyable, but it got me wondering if those changes, and the apparent emphasis on quantity over quality, was starting to hurt Disney as a business. So I took my newfound web-scraping skills to the Box Office Mojo website and Yahoo! Finance to see what the movie theater goers and stock holders had to say.
How has Disney been doing as a company over the last few years?
Disney does more than just movies, so let’s look at how the shareholders view Disney’s success. I got this stock data from Yahoo! Finance, and you can see that, other than the obvious dip caused by the pandemic in March of 2020, Disney was on the rise until around February 2021, then fell again November of 2021, and hasn’t gone above $130 since the beginning of 2022. Which incidentally aligns with the terror that was “Doctor Strange in the Multiverse of Madness” (May 2022). It could be coincindence though.
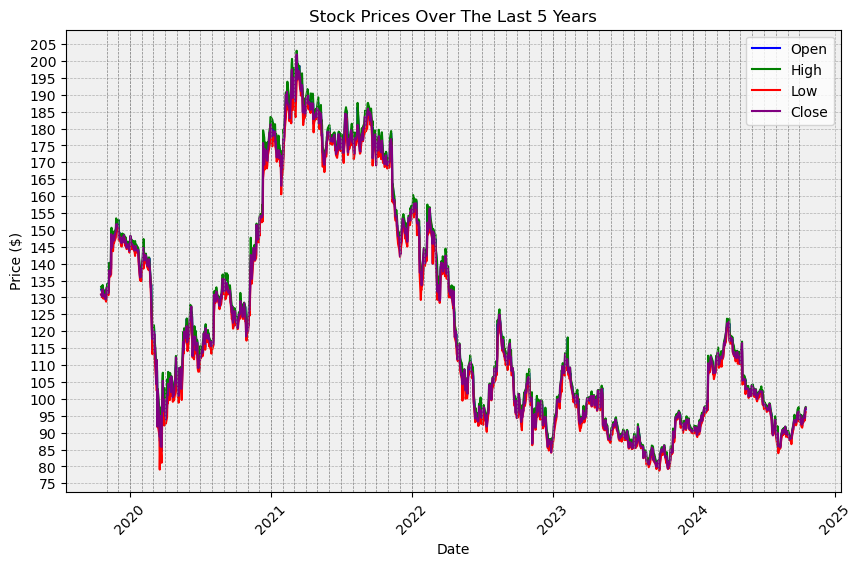
Because of the rise of inflation and the noteriaty of the company, Disney is still doing better than pre-2014, yet further evidence against them falling anytime soon. Loyal fans are still clinging on to the nostalgia of the past and the merch of the present, and there is no doubt that Disney is still a successful company. It’s just an interesting pattern to note before diving into the success of current movies.
A tale as old as Box Office numbers
Now that we have an overview of what the shareholders think, let’s look at what actual movie-goers think. Box Office Mojo has a really awesome collection of brands, their respective movies, and info about those movies’ lifetime gross income to date, max number of theaters, opening weekend gross income, opening number of theaters, release date, and distributer. It’s fun to look through their website, but I really wanted an aggregate of brands owned by disney, so I used web-scraping to look at the following brands from the Box Office Mojo Website:
- Marvel Comics – Disney acquired Marvel Entertainment in 2009.
- Lucasfilm – Disney purchased Lucasfilm in 2012.
- Pixar – Acquired by Disney in 2006.
- Walt Disney Animation Studios
- Blue Sky Studios – Disney acquired Blue Sky as part of the 2019 purchase of 21st Century Fox, but it was shut down in 2021.
- Disney Channel
- DisneyToon Studios – A division of Disney, closed in 2018.
- Disneynature
Mini Web-scraping tutorial for Python
When web-scraping data online, you must ALWAYS check the robots.txt file. It tells you what you can and should not scrape, and how fast you can scrape it. Nearly every domain has one, and if they don’t it is common curtesy to add a sleep timer. (Here is some example code since I didn’t need to use one in my web-scraping):
websites = []
for link in links:
time.sleep(10) # sleep timer for 10 seconds
r = requests.get(link)
bs = BeautifulSoup(r3.text)
try:
website = bs.find('div', {'class': 'unique_tag_text_from_html'}).find('a')['href']
except:
website = None
websites.append(website)
I checked robots.txt by using my RequestGuard class in python to check that the urls I was scraping from weren’t part of the forbidden list, but I recently learned about the urllib in python that can do the same thing for you. Check out this brief overview to learn more. Everthing was good for my urls so I moved on to the actual data gathering.
I used bs4.BeautifulSoup, but if the website you’re trying to scrape has buttons that need clicking, you’ll want to use Selenium.
Now you simply inspect the pages HTML by right clicking on the page, hovering over the HTML parts until the data you want to scrape is highlighted and find the unique tags attched to those data points. For readability, I’d also recommend converting the data to a pandas DataFrame.
My code looks like this:
url = "https://www.boxofficemojo.com/brand/bn3732077058/"
rg = RG(url)
if rg.can_follow_link(url):
print("robot.txt allows scraping for this page")
r = requests.get(url)
print(r.status_code) # if it's 200 we're good to go
soup = BeautifulSoup(r.text) # this gets the whole html soup object
container = soup.find('div', {'class': 'a-section imdb-scroll-table mojo-gutter'}) # a smaller chunk to make it easier to find names
Once you have a container, you get to play “find the pieces” with your data. When you know what the rows are contained in (usually something like a ‘tr’ table row tag.) Then you can iterate through and make a dataframe:
items = container.find_all('tr')
ranks, titles, gross, max_theaters, opening_earnings, opening_num_thtrs, release_dates, studios = [], [], [], [], [], [], [], []
for row in items[1:]:
rank = row.find('td', class_='mojo-field-type-rank').text
ranks.append(rank)
title = row.find('td', class_='mojo-field-type-release').text
titles.append(title)
life_gross = row.find # etc etc (check out repo for full code)
# combine the lists to make a pandas DataFrame
df = pd.DataFrame({'Rank': ranks, 'Title': titles, 'Gross Income': gross, 'Max Theaters': max_theaters, 'Opening Earnings': opening_earnings, 'Opening Num Theaters': opening_num_thtrs, 'Release Dates': release_dates, 'Studio': studios}).drop_duplicates().reset_index(drop=True)
Drum roll for the data pulled
After scraping the data from the different brands, I combined it into a csv with 204 movies, reranked them to align with the combination, and called it disney_owned_movies.csv. I realized that there were plenty of movies missing from the dataset not attatched to brands listed on Box Office Mojo, such as the Chronicles of Narnia movies, but my main points of interest revolved around Marvel, Pixar, and Walt Disney Animation, so I’ll leave adding the other Disney movies for you to explore if you’d like.
Without further ado, here are the highlights, and you can decide what you think of Disney’s fate. Only time will truly tell.
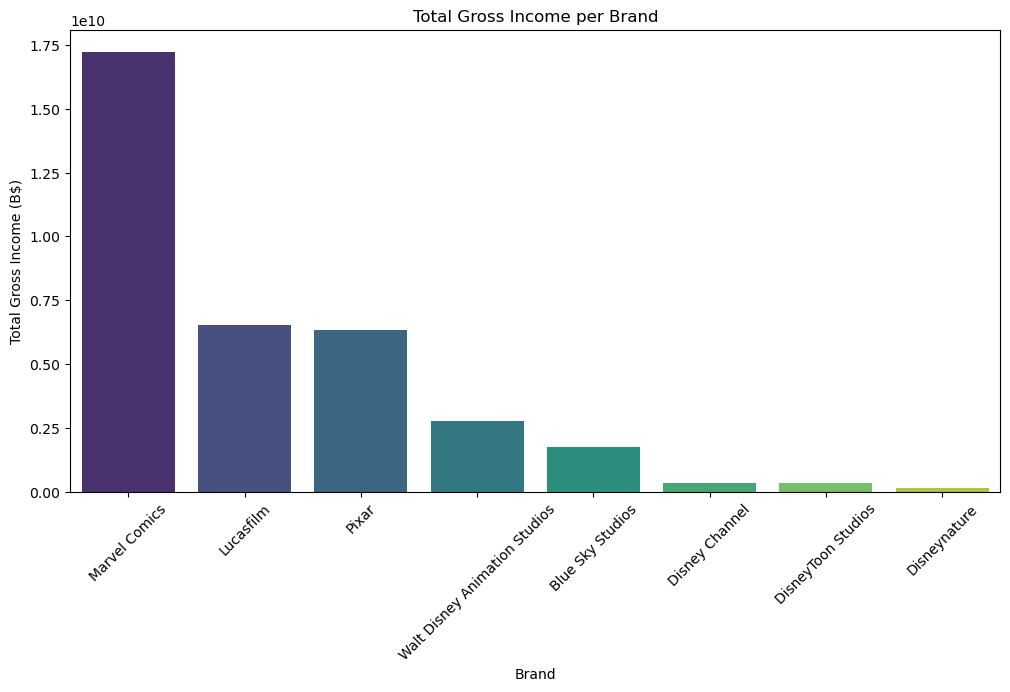
Marvel is clearly Disney’s highest grossing brand at the moment, so it was a wise purchasing descision, but it also means Marvel plays a huge role in Disney’s success.
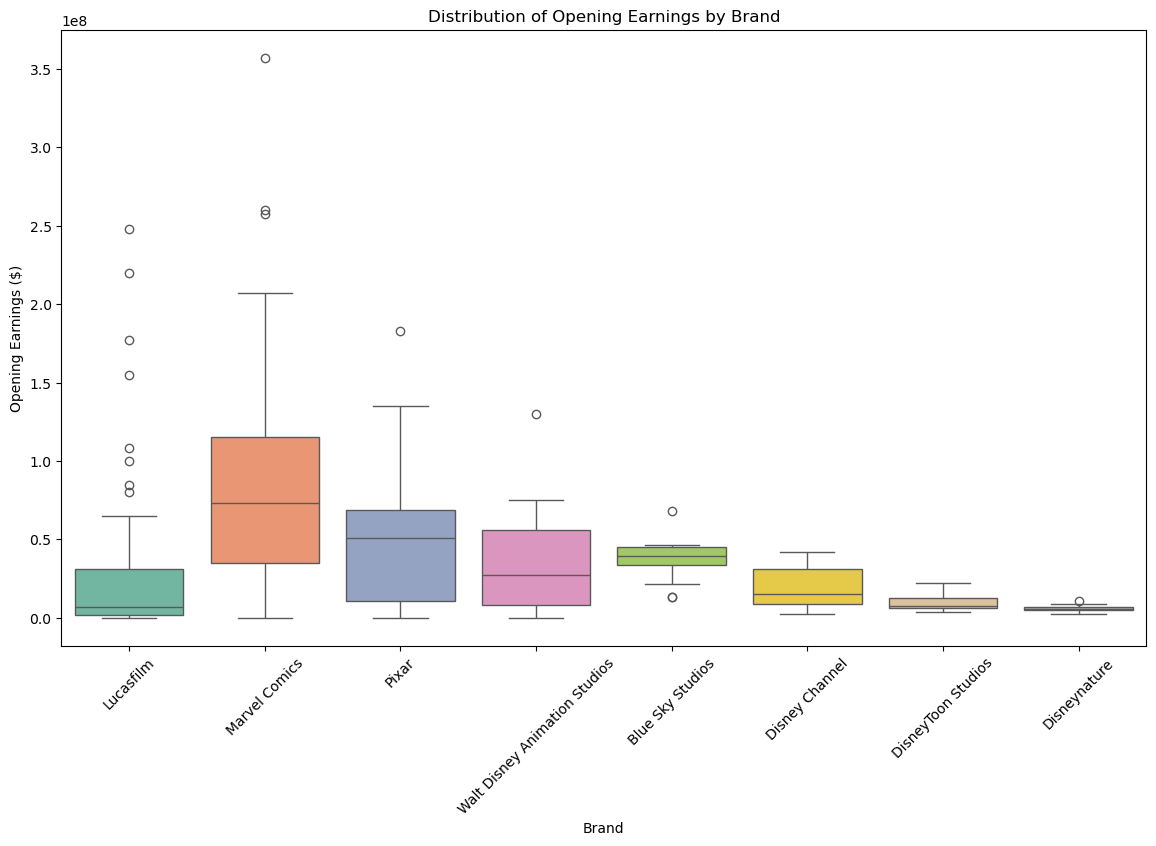
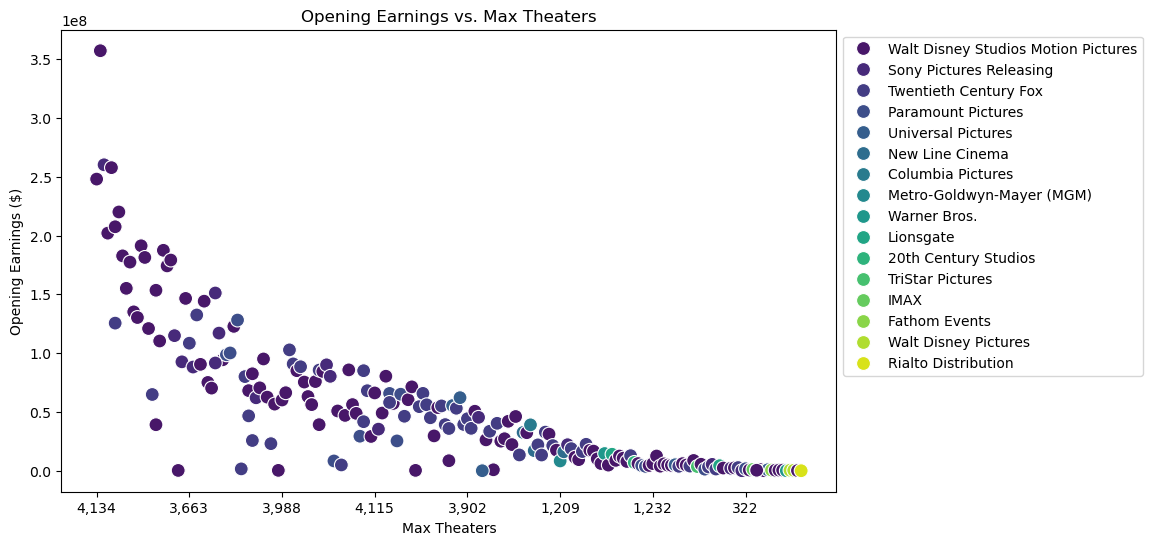
And the number of opening theaters doesn’t always spell success, but it is interesting to note the power of releasing studio influence.
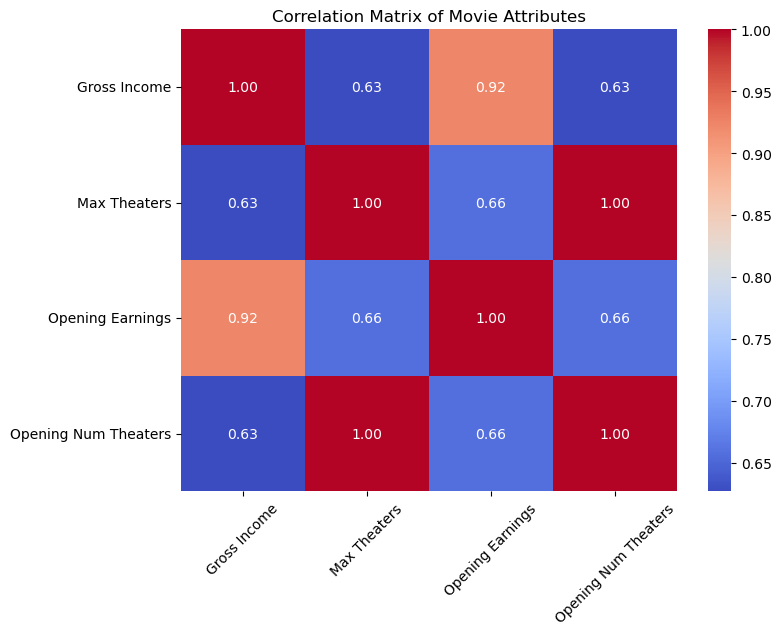
No surprise here, the movie attributes are pretty highly correlated (just look at the bottom left triangle) meaning that they’re all affected by the same thing or by each other.
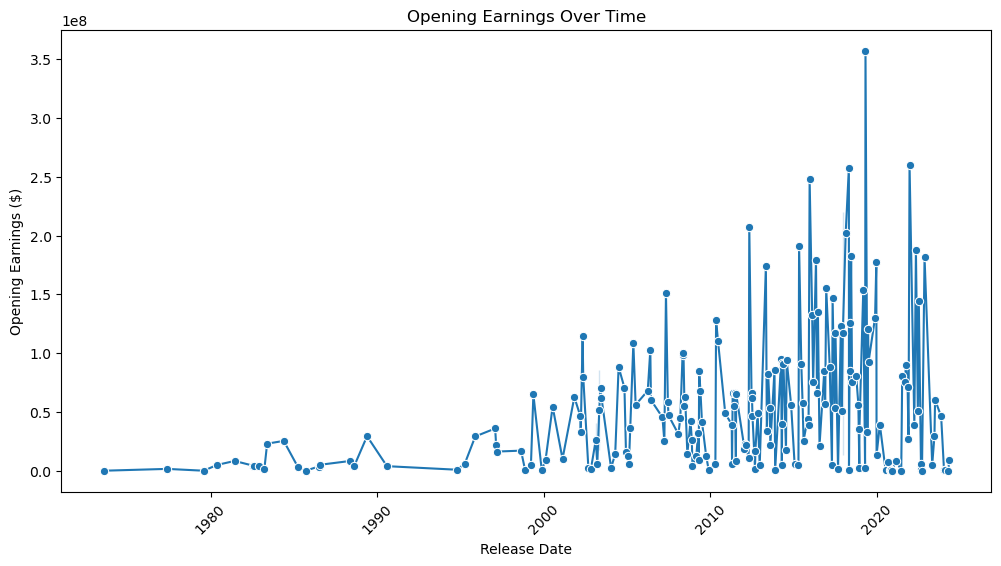
And the one we’ve all been waiting for, Opening Earnings over Time:
 And the zoomed in version:
And the zoomed in version:
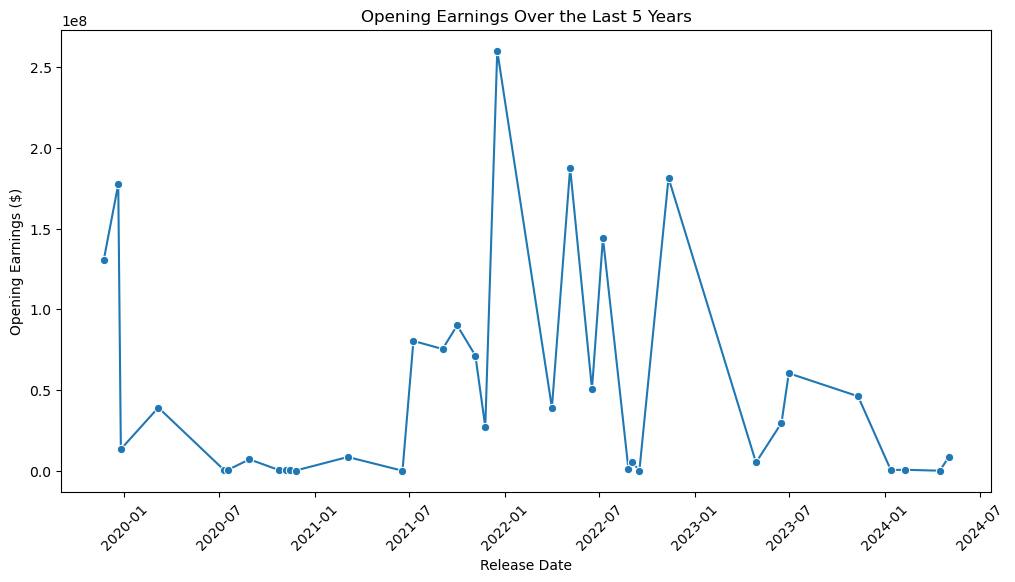
Notice the peaks in 2019 and 2022? Maybe I was right after all. The beginnings of a pattern are occuring and it doesn’t look too good for our heroes, especially when compared to the stock data we gathered earlier.
For lifelong Disney fans, this data might evoke nostalgia for the golden era of box-office hits, but hopefully there is more good to come. It makes one wonder how the company will innovate in response to these challenges. It will be interesting to see if Disney pivots its strategies or doubles down on its streaming services. Could this signal the end of Disney’s box-office dominance? Only time will tell.
Want to do it yourself?
Check out my repo with all of the code I used to webscrape the Box Offic Mojo website, my RequestGuard file for parsing the robots.txt files, the data I gathered, and some helpful links I found. Web scraping is a lot easier than I remembered it being, it just takes some puzzling and time. Go analyze data about your own interests, and always remember to have fun coding in color!